Full Coverage AI Advisor
Guidance grounded in RAG, flagship LLMs, and ongoing model evaluation on real quotes.
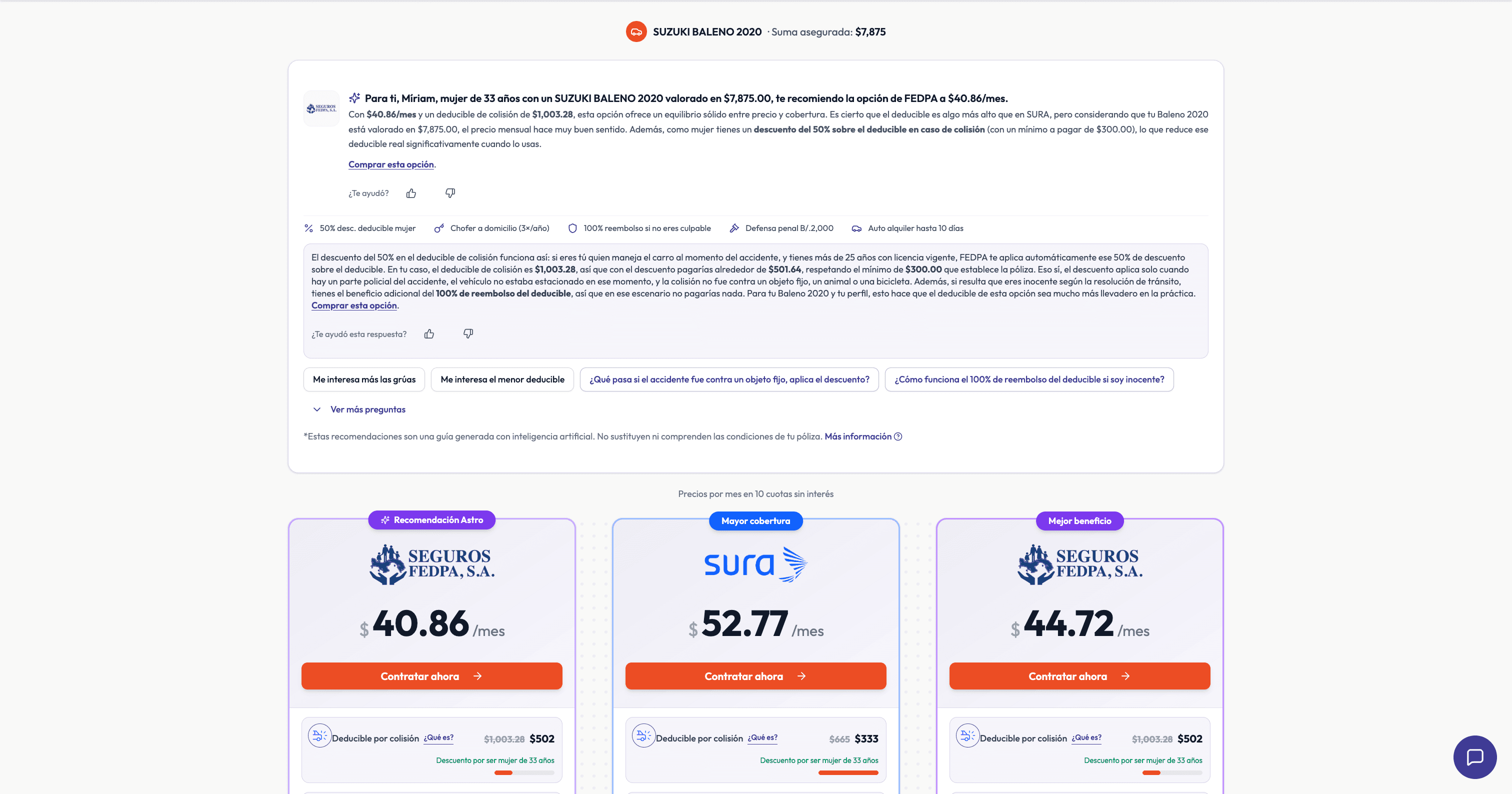
An AI assisted experience for full coverage auto at Astro Asistencias: recommendations and follow ups anchored to live quote data, with RAG over approved insurer documents when users ask about conditions, exclusions, or endorsements. Recommendations are reasoned with a MECE style frame (mutually exclusive decision dimensions that still cover what matters) so the assistant does not collapse into “always pick the cheapest.” Generation runs on flagship class models from major providers. The system is set up to evaluate those models in production, not only as a single benchmark. What the shopper sees is also stored in our CRM so the team can continue the conversation with full context.
Ships inside Astro’s full coverage auto journey. Same live site, dedicated product surface.
The problem
Multi insurer quotes are noisy. Shoppers drown in deductibles and benefits. Generic chatbots either hedge forever or invent coverage. The product needed guidance that feels personal but respects what is on the policy page, plus a way to know which flagship model and prompt setup actually hold up under traffic.
How the system works
User Question
Shopper asks about conditions, exclusions, or which plan
Route
Simple path (price) vs full RAG when policy language needed
Vector Search
Semantic search on embedded insurer-approved docs
Retrieve Chunks
Fetch relevant policy chunks from Postgres
LLM Generation
Answer with context, flagship models (OpenAI, Anthropic)
Output + CRM
Structured response to UI, sync to contact record
User Question
Shopper asks about conditions, exclusions, or which plan
Route
Simple path (price) vs full RAG when policy language needed
Vector Search
Semantic search on embedded insurer-approved docs
Retrieve Chunks
Fetch relevant policy chunks from Postgres
LLM Generation
Answer with context, flagship models (OpenAI, Anthropic)
Output + CRM
Structured response to UI, sync to contact record
Key features
Tech stack
Architecture
Next.js APIs, Vercel AI SDK, structured outputs for the UI, RAG pipeline (embeddings + vector store in Postgres/Supabase), brokerage stack for quotes and customer context, and CRM integration so AI outputs land on the record the team works from every day.
Learnings
RAG earns trust on fine print. The quote JSON still wins on benefits. A MECE style rubric stops the model from lazy “cheapest wins” answers and makes trade offs explicit. Flagship models are table stakes for quality, but without production side model evaluation you are flying blind on cost and regressions. Structured outputs plus telemetry turn live traffic into the real eval set.